
Pubblicare un articolo su un blog personale è facile. Assicurarsi che venga trovato dai motori di ricerca — e, sempre più, dai crawler AI — è un’altra storia. Per anni ho fatto come fanno tutti: scrivevo, applicavo il buon senso SEO di base, pubblicavo. Ogni tanto aprivo Google Search Console e se qualcosa era cambiato, o non stava funzionando, prendevo qualche contromisura seguendo, un po’ svogliatamente, le raccomandazioni di questo o quel tool di auditing.
Ecco, il fatto è che io, in quanto appassionato di divulgazione, trovo piacere a spiegare la scienza, e raggiungere l’audience più ampia possibile è parte del gioco. Ma il desiderio di scrivere, in me, vince sempre. L’ottimizzazione e, soprattutto, il monitoraggio arrivano irrimediabilmente dopo.
Così, oggi mi sono detto: perché non automatizziamo anche la componente SEO?
In un modo moderno, perbacco, già che siamo nel 2026?
…e possibilmente utilizzando solo strumenti open source o, al più, con un generoso free tier mensile?
In effetti, ogni volta che pubblico o modifico un post su questo blog, parte già una catena di eventi organizzata nel workflow di authoring e pubblicazione: Jekyll builda il sito, Cloudflare Pages lo pubblica, Cloudinary (la mia CDN) genera le immagini hero e scalda la cache con gli altri formati (quelli, ad esempio, per i microformati social). Tutto automatico, tutto già funzionante.
Si tratta solo di espandere il concetto.
Così è nata la mia pipeline di SEO automatica, la prima di una serie che nella mia testa avrà, in definitiva, questi tre blocchi:
- Il supporto all’autorialità. Quello che vedremo oggi: una pipeline che alla pubblicazione di un nuovo articolo effettua una serie di audit ed altre operazioni sullo stesso, proponendo eventuali azioni migliorative.
- Il supporto al monitoraggio. Un workflow periodico che, anche in assenza di nuovi articoli, monitora i parametri SEO ed evidenzia problemi o cambiamenti peggiorativi nello stato di salute del blog nel suo complesso.
- L’applicazione automatica delle migliorie. In cui agenti LLM andranno ad analizzare le proposte di migliorie SEO emerse nel blocco 1 e applicheranno automaticamente i correttivi, per poi valutarne l’effetto grazie al monitoraggio del blocco 2.
Il workflow di supporto autoriale: l’idea
Banalmente, una volta terminato il processo di pubblicazione di un articolo, il suo permalink viene passato a una serie di servizi che lo analizzano e lo notificano ai motori di ricerca. Il tutto orchestrato da un unico file YAML. Zero servizi a pagamento, zero login da fare, zero dashboard da aprire, zero notifiche da controllare manualmente — tutto descritto programmaticamente dal contenuto del repository git e guidato da CICD.
In questo articolo non andrò a riportare il codice nella sua interezza, per non appesantire la lettura, ma solo i suoi principi di base e le sue caratteristiche più istruttive. Chiaramente, sentitevi liberi di riutilizzare il workflow secondo le vostre esigenze: ne sarei felice!
Come funziona
Innanzitutto, il workflow si aggancia a workflow_run, cioè parte automaticamente al completamento del workflow precedente, quello di pubblicazione, appunto. Può, però, anche essere lanciato manualmente passando gli URL da verificare mediante una clausola di workflow_dispatch.
Questo, nello YAML del workflow, è espresso tramite questo blocco in testa:
on:
workflow_run:
workflows: ["Deploy blog on Cloudflare Pages"]
types: [completed]
branches: [main, master]
workflow_dispatch:
inputs:
urls:
description: 'URL da verificare (separati da spazio)'
required: false
type: string
Ogni job avrà sempre una clausola if di questo tipo:
if: ${{ github.event_name == 'workflow_dispatch' || github.event.workflow_run.conclusion == 'success' }}
Ma la parte più elegante è il modo in cui trova i post da analizzare:
git diff --name-only HEAD~1 HEAD -- '_posts/**.md' '_posts/**.Rmd'
In pratica, prende solo i file .md e .Rmd modificati nell’ultimo commit e di questi estrae la categoria e lo slug dal nome file, costruisce la lista di URL da testare e poi uno ad uno chiama i vari servizi passandogli la lista, oppure un URL alla volta in un loop bash. Nessun inventario da mantenere.
Gli url di chiamata sono costruiti tramite operazioni su stringhe, i servizi li chiamo tutti tramite curl, e formatto i risultati con jq e li mostro a console. È tutto scritto in bash, insomma.
Se la maggior parte dei tool producono solo un po’ di informazioni in stdout che io riformatto e stampo, altri producono output molto più ricchi. Per questi ultimi, salvo i report come artifact del workflow, accessibili dalla pagina dell’azione su GitHub per 30 giorni. Un esempio:
- name: Salva report Lighthouse
if: always()
uses: actions/upload-artifact@v4
with:
name: lighthouse-reports
path: |
lighthouse-results/
.lighthouseci/*.html
.lighthouseci/*.json
retention-days: 30
Ma adesso scendiamo nel dettaglio pratico su ciò che facciamo e perché lo facciamo.
Le cose che contano davvero
Ho colto l’occasione di questa pipeline per sistemare diversi aspetti di SEO strutturale (layout) che erano in arretrato da tempo. Non sono interventi appariscenti, ma sono quelli che fanno la differenza tra un blog tecnicamente solido e uno che spera di essere trovato. Prima i fondamentali, insomma.
Parte 1 — Crawlability e l’arte di farsi trovare
Trovarsi su Google non basta più. Nel 2026, una fetta crescente del traffico verso i contenuti tecnici arriva dai crawler AI — ChatGPT, Perplexity, Claude, Gemini, Copilot. Questi sistemi non navigano il web come un browser: arrivano, leggono l’HTML e se ne vanno. Se il tuo contenuto non è immediatamente accessibile, per loro non esiste.
Secondo AI Advisors, i crawler AI cercano tre cose: contenuti ben strutturati, segnali di autorità chiari, e una gerarchia di heading che renda ovvio di cosa parla ogni sezione. Non è diverso da ciò che vuole Google, ma è più esigente in termini di pulizia strutturale e metadati.
Ne ho approfittato quindi per sistemare, lato template Jekyll, questi elementi statici:
robots.txt per crawler AI. GPTBot, CCBot, anthropic-ai, PerplexityBot, Google-Extended e altri: tutti possono accedere ai contenuti testuali ma non agli asset binari. Con l’esplosione del traffico da AI crawler, è diventato rilevante. Ma attenzione a non stressare troppo la CDN: il traffico da AI può essere davvero invadente.
llms.txt e llms-full.txt. Il primo è un indice strutturato dei post in formato Markdown — una specie di sitemap per LLM. Il secondo è l’intero corpus del blog in un unico file markdown, generato automaticamente a ogni build da un semplicissimo plugin Jekyll. Lo standard è ancora acerbo e usato da pochi attori (solo OpenAI, al momento in cui scrivo), ma adottarlo costa talmente poco che non farlo sarebbe pigrizia.
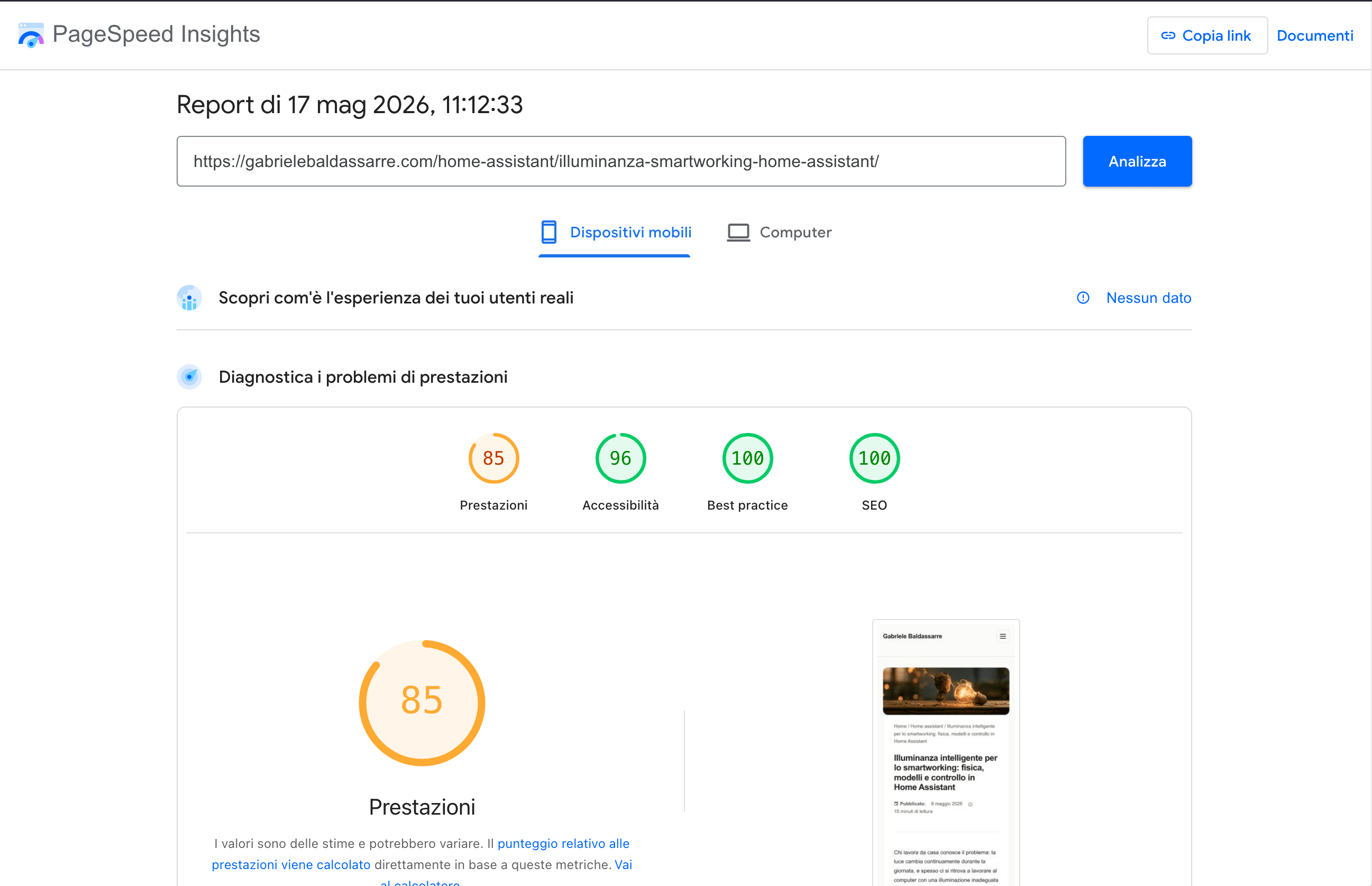
Core Web Vitals sotto controllo. Lighthouse CI e PageSpeed Insights verificano a ogni deploy che LCP (Largest Contentful Paint), CLS (Cumulative Layout Shift) e TBT (Total Blocking Time) restino entro soglie accettabili. Le mie pagine sono statiche, quindi i valori sono naturalmente buoni, ma il controllo automatico mi avvisa se qualcosa degenera — un’immagine troppo pesante, un font che blocca il rendering, un layout che slitta, un javascript che crea problemi.
Parte 2 — Schema.Org e l’arte di farsi riconoscere
I microformati sono il modo in cui dici ai motori di ricerca cosa stai dicendo. Non “questa è una stringa di testo”, ma “questo è il titolo di un articolo, questo è l’autore, questo è un termine tecnico definito e questo sono io”.
Sul mio blog, ogni post ha già un blocco JSON-LD BlogPosting con titolo, descrizione, data di pubblicazione, autore. Quello che ho aggiunto con questa pipeline è:
author.sameAs. I link ai profili social dell’autore (GitHub, LinkedIn, Mastodon, Goodreads, Printables) ora appaiono nel markup strutturato. Per i motori di ricerca, questo collega inequivocabilmente i contenuti a una persona reale con una presenza online verificabile.
{
"@context": "https://schema.org",
"@type": "Person",
"name": "Gabriele Baldassarre",
"url": "https://gabrielebaldassarre.com",
"image": "https://gabrielebaldassarre.com/assets/images/gabriele-baldassarre.png",
"sameAs": [
"https://github.com/theclue",
"https://www.linkedin.com/in/gabrielebaldassarre",
"https://mastodon.social/@gabriob",
"https://goodreads.com/theclue",
"https://www.printables.com/@GabrioB_1701666"
]
}
Ho creato un glossario YAML (_data/glossary.yml) con i termini tecnici che uso più spesso nel blog — spin quantistico, autovettore, illuminamento, legge di potenza, ecc. — ciascuno con definizione e URL sotto forma di entità DefinedTerm e DefinedTermSet. Ogni post ora ha un blocco about che linka i termini del glossario pertinenti alla categoria. Sulle pagine indice (homepage, categorie), un DefinedTermSet elenca l’intero glossario.
{
"@type": "DefinedTermSet",
"name": "Glossario di Gabriele Baldassarre",
"hasDefinedTerm": [
{
"@type": "DefinedTerm",
"termCode": "Spin quantistico",
"name": "Spin quantistico",
"description": "Proprietà intrinseca delle particelle elementari...",
"url": "https://gabrielebaldassarre.com/fisica/stati-spin/"
}
]
}
L’obiettivo è costruire un mini knowledge graph semantico, così che un motore di ricerca — o un LLM — che atterra su una mia pagina possa risalire al contesto tecnico in cui si inserisce.
Dopo aver definito il proprio modello di metadati di schema, non fa male fare un passaggio su Schema Validator.

Parte 3 — GEO e l’arte di farsi capire
La Generative Engine Optimization (GEO) è la pratica di strutturare i contenuti perché vengano citati dai motori di ricerca AI — ChatGPT, Perplexity, Claude, Gemini. Non si tratta di ranking. Si tratta di citation rate: quanto spesso il tuo brand appare nelle risposte generate.
Secondo LLMrefs, la sovrapposizione tra i link di Google e le fonti citate dagli AI è scesa dal 70% a meno del 20%. In particolare, le AI citano tranquillamente risultati che, invece, nelle SERP dei motori di ricerca sono ben lontane dalla prima pagina di risultati, senza timore. I due mondi si stanno separando. E i criteri che usano gli AI per scegliere cosa citare sono diversi.
Cosa ho fatto, in concreto, per applicare GEO al mio blog:
- Heading gerarchici puliti. Ogni sezione ha un H2, ogni sottosezione un H3. Un argomento per sezione. Gli AI usano la struttura per decidere cosa è rilevante.
- Risposte prima del contesto. In ogni sezione, la risposta arriva subito, il contesto dopo. Gli AI estraggono informazioni, non leggono romanzi. E qui la sfida per me sta proprio nello scrivere un testo un minimo sospensivo che crei pathos per il lettore, ma che non sia penalizzato dalle AI. Spoiler: non è per niente facile (ma ci si riesce).
- Paragrafi corti. Due o tre frasi al massimo. I blocchi di testo lunghi sono più difficili da processare, meno probabili da citare e occupano più contesto (“Che, signora mia, di contesto non ce n’è mai abbastanza!”).
- Liste puntate e numerate. Per processi, checklist, confronti.
- Segnali di autorità espliciti. L’autore è indicato con nome, biografia e link social. Le fonti sono citate. I dati hanno attribuzione. I microformati rafforzano l’ancoraggio identitario. Molto utile.
- Freschezza dei contenuti. Gli AI hanno un recency bias fortissimo: dopo 3 mesi, le citation crollano. Per questo motivo il workflow di monitoraggio (blocco 2) includerà un check periodico sulla freschezza.
Non ho dovuto snaturare il mio modo di scrivere. Ho solo applicato un po’ di disciplina strutturale. Che, a ben vedere, migliora la lettura anche per gli umani.
Parte 4 — SEO Auditing e l’umiltà di farsi consigliare
Arriviamo al cuore pratico della pipeline. Una volta che il workflow ha trovato i post da analizzare, per ognuno chiama in sequenza questi quattro servizi.
IndexNow
È il più semplice: un POST JSON con {host, key, urlList} a api.indexnow.org. La chiave è un file .txt servito alla root del dominio che dimostra la proprietà del sito — niente registrazioni, niente dashboard. Il protocollo è adottato da Bing, e questo ci basta:
curl -X POST "https://api.indexnow.org/indexnow" \
-H "Content-Type: application/json; charset=utf-8" \
-d '{"host":"gabrielebaldassarre.com","key":"b8f09512...","urlList":["https://gabrielebaldassarre.com/fisica/stati-spin/"]}'
La risposta è un 200 se l’URL è stato accettato, 202 se è in attesa di validazione della key (la prima volta che si usa). Dopo il primo invio, la key è verificata e le risposte successive sono tutte 200 (quindi si, se usate il mio workflow la prima volta la pipeline fallirà. Sappiatelo).
🚀 Invio notifica IndexNow per 1 URL...
📥 Risposta IndexNow: HTTP 200
✅ URL notificati con successo ai motori di ricerca
Hermes SEO Audit
Un’API pubblica (con key opzionale per limiti più alti — 5 req/giorno anonimo, 50 con key gratuita). Restituisce un JSON con score, grade, issues, warnings e passed. Lo uso per avere un quadro immediato dello stato SEO di una pagina.
curl -s "https://hermesforge.dev/api/seo?url=https://gabrielebaldassarre.com/fisica/stati-spin/&key=YOUR_KEY"
Output a console dopo parsing con jq:
📋 [1/2] https://gabrielebaldassarre.com/fisica/stati-spin/
Punteggio: 94/100 (A)
Problemi: 0 | Warning: 2 | OK: 10
🟡 Warning:
- [title] Title may be truncated in search results (114 chars)
- [meta] Meta description may be truncated (213 chars)
📊 Riepilogo: 94/100 (A) | 🔴 0 | 🟡 2 | ✅ 10
📋 [2/2] https://gabrielebaldassarre.com/home-assistant/illuminanza-smartworking/
Punteggio: 85/100 (B)
Problemi: 1 | Warning: 3 | OK: 8
🔴 Problemi:
- [images] 1 of 1 images missing alt text (high)
🟡 Warning:
- [title] Title too short (38 chars, recommend 50-60)
- [meta] Meta description short (89 chars)
- [performance] Page size excessive (1.2 MB)
📊 Riepilogo: 85/100 (B) | 🔴 1 | 🟡 3 | ✅ 8
Hermes è, in realtà, una suite ben più grande — offre anche screenshot API, chart rendering, dead link check e performance audit — con caratteristiche davvero intriganti e su cui sicuramente scriverò in futuro.
PageSpeed Insights
L’API ufficiale Google per Core Web Vitals. Richiede una API key gratuita da Google Cloud Console. Restituisce le categorie performance, accessibility, SEO e best-practices, sia per mobile che per desktop.
curl -s "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=https://gabrielebaldassarre.com/&strategy=mobile&category=performance&category=accessibility&category=seo&category=best-practices&key=YOUR_KEY"
Nota bene: bisogna passare esplicitamente le quattro categorie con &category=, altrimenti l’API restituisce solo performance. Ci ho perso due ore a capirlo e vi risparmio volentieri questo strazio.
Output a console:
🔍 Analisi: https://gabrielebaldassarre.com/
📱 Mobile | Perf: 89% | A11y: 92% | SEO: 83% | LCP: 3.8 s | TBT: 10 ms | CLS: 0
🖥️ Desktop | Perf: 98% | A11y: 92%
🔍 Analisi: https://gabrielebaldassarre.com/fisica/stati-spin/
📱 Mobile | Perf: 82% | A11y: 88% | SEO: 79% | LCP: 4.3 s | TBT: 60 ms | CLS: 0.104
🖥️ Desktop | Perf: 100% | A11y: 88%
⚠️ PERFORMANCE MOBILE SOTTO SOGLIA CRITICA: 82%
Il report JSON completo — ben più ricco della sintesi a console — viene salvato come artifact del workflow, accessibile per 30 giorni.
Lighthouse CI
Qui cominciamo a calare i pezzi grossi. Lighthouse CI non è un servizio remoto con una API REST, ma un headless Chrome eseguito in locale sulla VM del runner di GitHub Actions. Naviga le pagine, raccoglie metriche, e produce report HTML con screenshot, waterfall di rete e diagnostica.
npm install -g @lhci/cli --quiet
npx lhci collect --url="https://gabrielebaldassarre.com/fisica/stati-spin/" \
--settings.chromeFlags="--no-sandbox --headless --disable-gpu" \
--numberOfRuns=1
npx lhci assert --config=.github/lighthouse/lighthouserc.json
Le assertion sono configurate in un file lighthouserc.json che definisce le soglie minime:
{
"ci": {
"assert": {
"assertions": {
"categories:performance": ["warn", {"minScore": 0.50}],
"categories:accessibility": ["warn", {"minScore": 0.80}],
"categories:seo": ["warn", {"minScore": 0.70}],
"largest-contentful-paint": ["warn", {"maxNumericValue": 4000}],
"total-blocking-time": ["warn", {"maxNumericValue": 500}],
"cumulative-layout-shift": ["warn", {"maxNumericValue": 0.25}]
}
}
}
}
Essendo un tool locale, ipoteticamente potrebbe anche essere eseguito a build time prima della pubblicazione, e magari bloccarla se il post non raggiunge una soglia minima di score. All’atto pratico, però, questo scenario non è facile da implementare.
Nel mio caso, ad esempio, che uso una CDN per le immagini, durante il build gli asset non sono ancora pubblici e i loro URL non sono ancora risolti. L’audit pre-deploy soffrirebbe di falsi positivi. Eseguo quindi Lighthouse post-deploy, quando il sito è live e Cloudinary ha già cachato tutte le immagini.
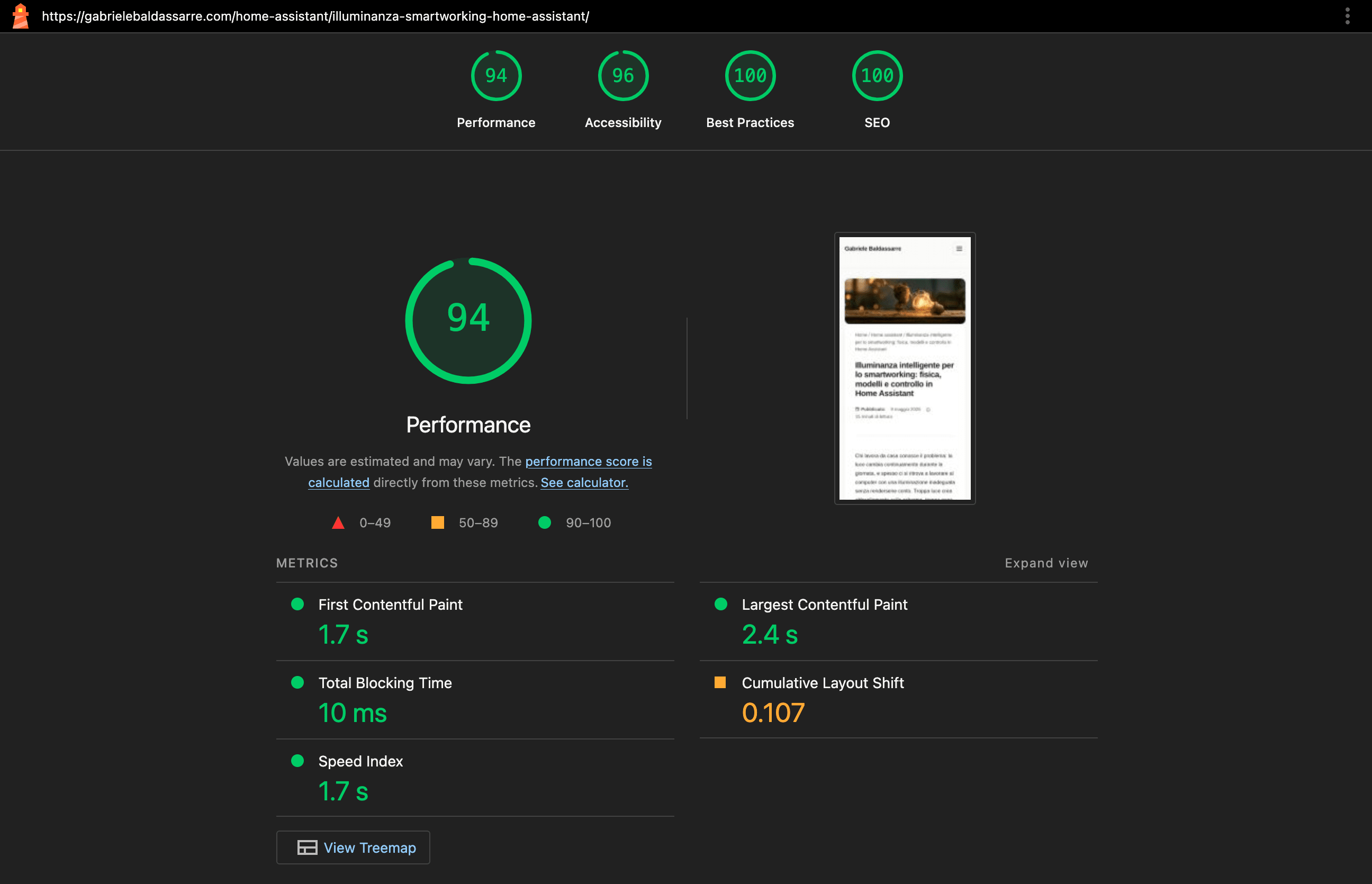
I report HTML e JSON sono salvati come workflow artifact con timestamp e commit hash nel nome (assertions-20260516-164500-a1b2c3d.json), da dove li recupero per un’ispezione ad oggi manuale. Sono incredibilmente ricchi di informazioni. Forse anche troppe, per un umano… se capite dove voglio arrivare.
Gestire secrets e API key
Molti di questi servizi richiedono un’API key, spesso passata come parametro nelle chiamate curl. Come le si passa al workflow senza committare in chiaro sul repository?
Ma con le Secrets ovviamente! Anche Github, infatti, ha questa funzionalità che non può mancare ad un orchestratore di CICD. Si configurano in Settings → Secrets and variables → Actions.
Quanto costa
Zero. Ecco il conto, servizio per servizio:
- GitHub Actions — illimitato per repository pubblici. 2000 minuti/mese di esecuzione; ne consumo forse 30.
- PageSpeed Insights — 25.000 query al giorno. Ne faccio 4 o 5 a deploy.
- IndexNow — completamente gratuito e senza limiti.
- Hermes SEO — 5 richieste al giorno in anonimo, 50 con API key gratuita.
- Lighthouse CI — eseguito localmente sul runner di GitHub Actions, nessun servizio esterno.
Prossimi passi
Questo era il blocco 1: supporto all’autorialità. Nel prossimo articolo della serie affronterò il blocco 2, il monitoraggio periodico: un workflow schedulato con cron che testa tutti i post del blog una volta al mese, produce un report aggregato, e — se necessario — apre automaticamente una issue su GitHub per segnalare regressioni.
Poi, nel blocco 3, arriverà la parte più ambiziosa: un agente LLM che analizza i report SEO, propone modifiche ai post, le applica in una pull request, e verifica l’effetto grazie ai dati del monitoraggio.
Ma per oggi va bene così.